Customized telemetry for complete software reliability. Automatically.


Goodbye observability bloat. Hello context-aware reliability.
Observability bloat is crippling
Proactive, business-aware reliability so your teams can focus on building
See Sylogic in Action
Watch how our AI-powered observability transforms your monitoring workflow in real-time

Ready to transform your observability?
Get Early AccessGive your SREs superpowers
Remove risks of lost tribal-knowledge and 'What changed?'
Always on the lookout for what’s missing. Offers fixes.
Continuous drift protection.
Slash costs and future-proof with open source. But only when you're ready.

Define your needs. Sylogic's AI does the rest.
Define Your Intent
Suggests SLO Implementation
Enhances Existing Observability
Continuous Learning
Expand your observability team, without expanding headcount
Add Hyperscaler expertise to your stack
Our team built observability at scale for the world's most demanding environments. Now, that expertise powers your success.





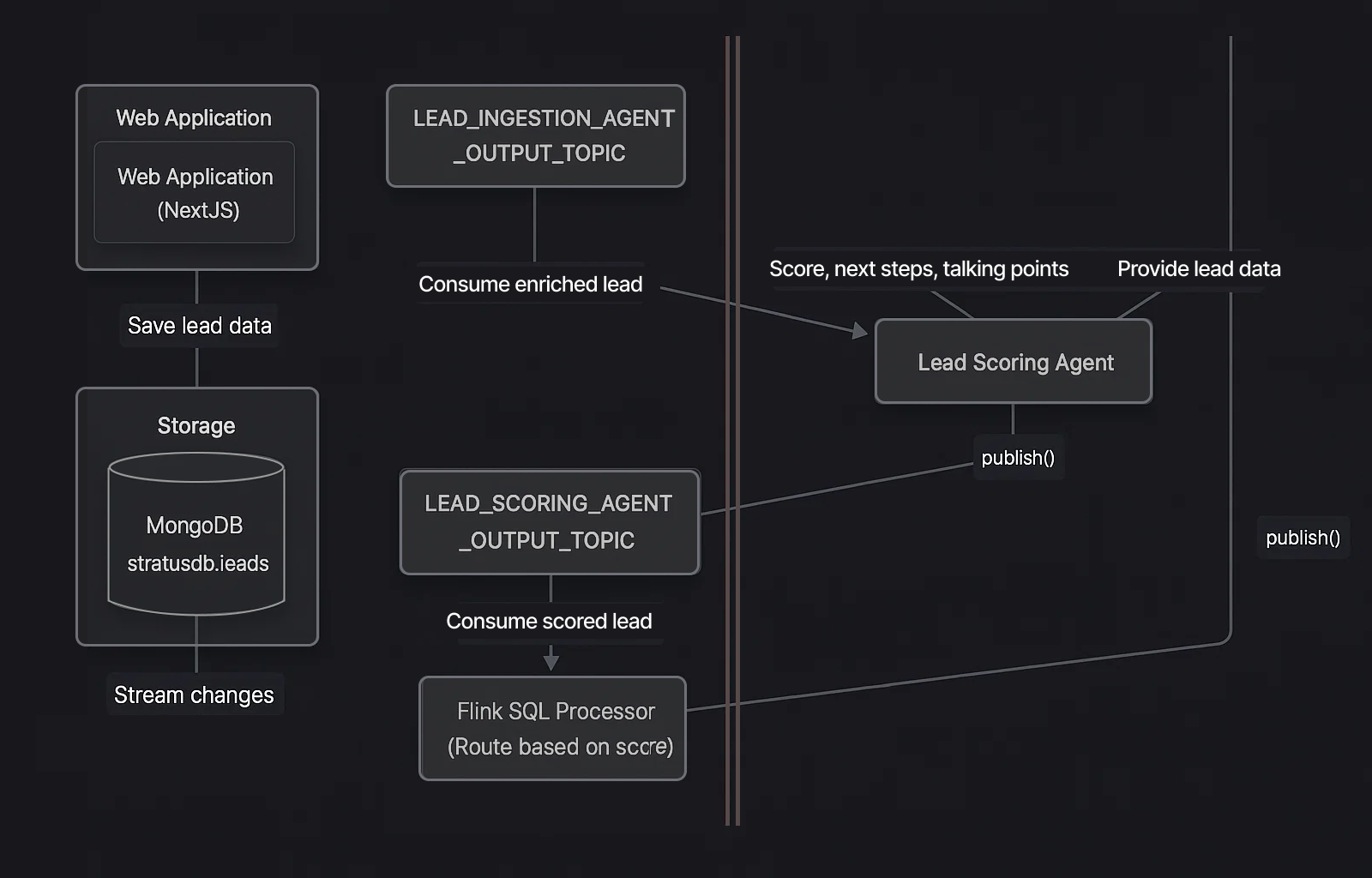
Business-aware telemetry that accelerates product development
Add business-context rich traces in your code. No more grepping infinite logs to find the bug in your micro-services.
Enforce SRE best practices across all your apps
Centralized, SLO-driven automation of the observability posture across your organization. Sylogic detects any config or code changes and immediately recommends adjustments to telemetry to maintain your standards.
Reduce the cost of operating observability
Automate repetitive labor prone to human error. Reduce the "firehose" by collecting just the data you need.
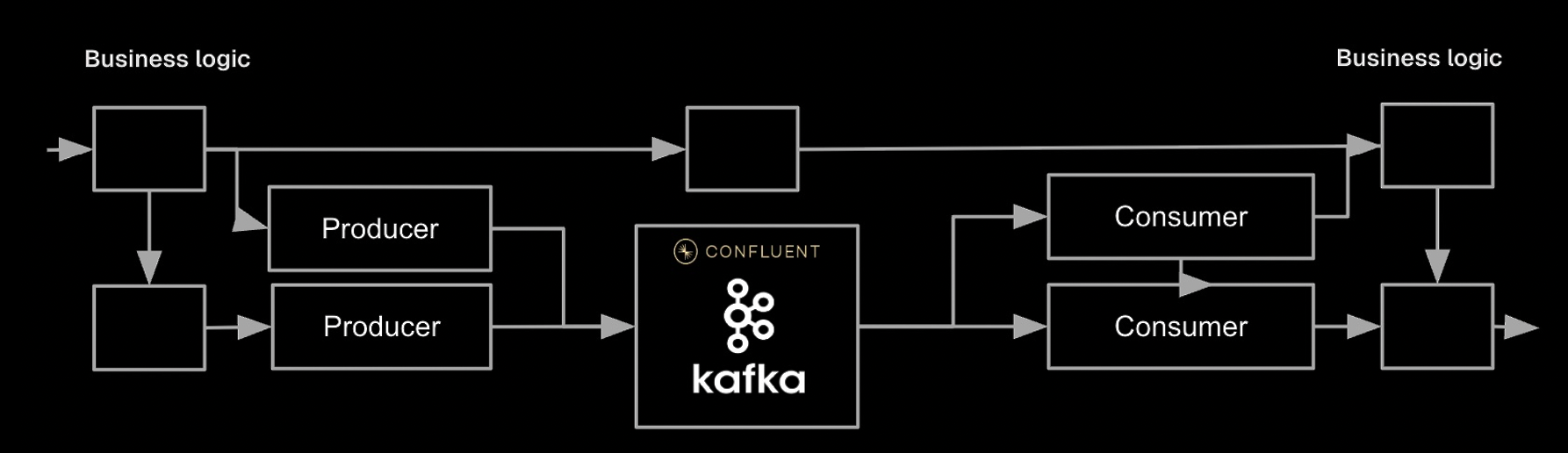
Integrates into your existing stack
Sylogic learns about your context from code repos, tickets, documents and conversations, and interfaces with your observability platform to optimize code instrumentation and data pipelines.
The AI observability landscape
General AI copilots?
Observability vendor AI agents?
Sylogic AI
Simple to evaluate, deploy & scale
Run Trial in Minutes
Connect a Github repo. Run a coverage and gap analysis. Identify ROI and impact. Risk-free evaluation: read-only access, no cost.
Platform Rollout in Days
Implement new policies. Manage your observability posture with our agents. Optionally migrate to open source.
Faster Innovation...
Sylogic automates proactive reliability standards across the organization so your teams can focus on building. Business-IT alignment achieved!